Veeam v7 has been out for sometime now, but I have only now managed to get around to starting the upgrades to our existing v6.5 installations.
One of the new features available in v7 is Parallel Processing :-
One big performance improvement in v7 is parallel processing within a backup job. Previously, all VMs were processed serially. In v7 they’re processed in parallel and even better, multiple virtual disks on the same VM are processed in parallel
So I was keen to see the feature in the action, but there is a gotcha. When upgrading from a previous version to v7, the feature is disabled by default. This is by design, to stop any unexpected changes. Enabling the feature is very straight forward , as with most things Veeam related.
1. Log into the Veeam Management console
2. Click on the drop down menu in the top left hand corner
3. From the menu select ‘Options’
4. From the options screen, select the ‘Advanced’ tab and ensure the ‘Parallel processing’ tick box is checked.
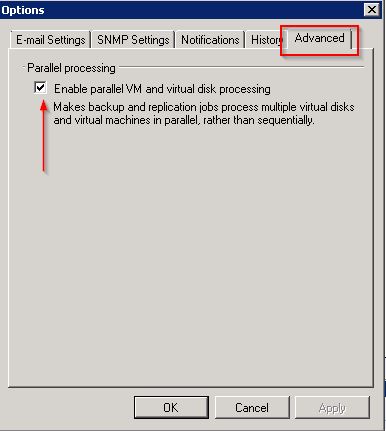
4. Click OK to complete.
Another point worth noting is Veeam mention a new compression alogorithm :-
In addition, we’ve improved our default compression algorithm by a huge factor, meaning you can now process up to 2x more tasks per proxy than in v6. This also means much less CPU load on the proxies
To allow your existing jobs to activate this new algorithm you will need to run a new full backup to activate it. Again this only applies to upgrades from previous versions of Veeam, and is by design for the same reason as previously mentioned.
**UPDATE***
It would appear I misunderstood the requirement for using the new algorithm. When jobs from v6.5 are set to use ‘Optimised’ compression, this is moved up to ‘High’ in v7. To utilise the new compression algorithm the upgraded job needs to be changed to ‘Optimised’ in the backup job.
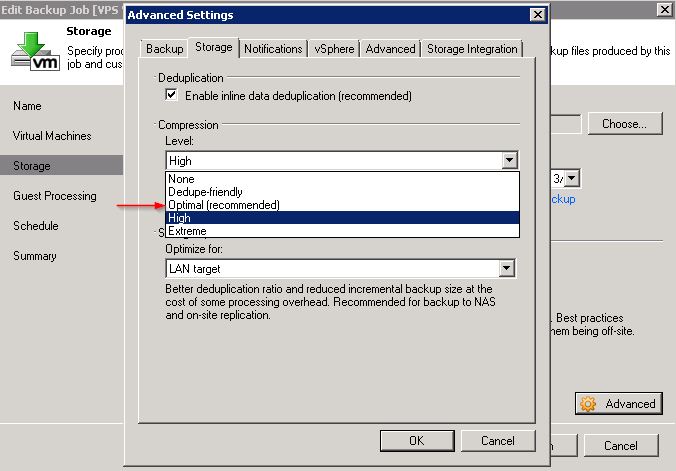
See http://forums.veeam.com/viewtopic.php?f=2&t=17611&p=85444&hilit=optimal+high#p85441 for more indepth explanation and disucssion.
The new compression algorithm reduces the CPU utilisation, but allows more data to be processed. Some users are reporting their backup windows have remained similar but the amount of data processed has in some cases doubled. Pretty impressive. I look forward to seeing similar figures in my production system.
Thanks for the post, Craig. Actually, I don’t believe the full backup is required to activate the new compression level. I know someone on forums have said that, but I don’t believe it’s true 😉
Ok, taking a full backup to enable to new compression algorithm was a suggestion from someone within Veeam. I hope I haven’t dropped anyone in ‘it’ 😉
Of course not ! its rare for @gostev to be wrong – it was more likely a case of an internal miss-communication, but it is worth checking to find the ultimate definitive answer !
If the full backup is not required , then it is great news for anyone upgrading.